译者 | 布加迪
审校 | 重楼
当 您 浏览 Twitter 、 LinkedIn 或新闻 源 上的时间轴时,可能会看到一些关于聊天机器人、 LLM 和 GPT 的内容。因为每周都有新的 LLM发 布 , 很多人都在谈论 LLM 。
我们目前 置身于一场 人工智能革命,许多新应用都依赖于 向量 嵌入。 不妨 让我们更多地了解向量数据库以及为什么它们对 LLM 很重要。
向量数据库 的定义
不妨 先定义 向量嵌入( V ector E mbedding) 。向量嵌入是一种数据表示,它携带语义信息,帮助人工智能系统更好地理解数据,并能够保持长期记忆。对于任何 您 想学的新东西,最重要的 部分 是理解并记住 主题。
嵌入是由人工智能模型生成的, 比如 含 有 大量特征的 LLM ,这使得它们的表示难以管理。嵌入表示数据的不同维度,以帮助 AI 模型理解不同的关系、模式和隐藏结构。
使用 基于标量的 传统 数据库 的向量嵌入是一个挑战,因为它 无法处理或跟上数据的规模和复杂性。 鉴于向量 嵌入 具有 的 种种 复杂性, 不难 想象它需要专门的数据库。这 时候 向量数据库 就有了用武之地 。
向量 数据库为 向量 嵌入的独特结构提供了 经过 优化的存储和查询功能。它们提供简单的搜索、高性能、可 扩展 性和数据检索, 这一切 都是通过比较值和查找彼此之间的相似性来实现的。
是不是 听起来很棒 ? 有一种方法可以处理 向量 嵌入的复杂结构。 不过 向量数据库很难实现。
就在不久前 ,向量数据库 还 只被那些不仅有能力开发而且有能力管理的科技巨头 所 使用。向量数据库 成本高昂, 因此确保它们 经过 正确校准对于提供高性能非常重要。
向量数据库是如何工作的 ?
现在我们对 向量嵌入 和 向量 数据库有了 一定的 了解, 不妨 看看它是如何工作的。
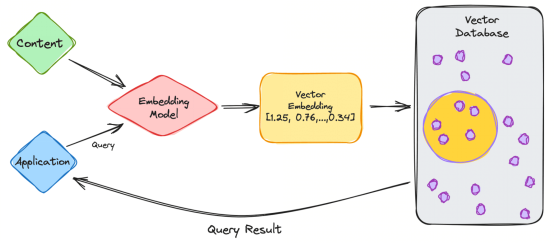
不妨 从一个处理 ChatGPT 等LLM的 简单示例开始。该模型有大量的数据和大量的内容,它们为我们提供了 ChatGPT 应用程序。
不妨 看看这些步骤。
1. 作 为用户,您将 往该 应用程序输入查询。
2. 然后 您的 查询 被 插入到嵌入模型中,该模型基于我们想要索引的内容创建 向量 嵌入。
3. 然后 向量嵌入移 动到 向量 数据库中 。
4. 向量数据库 生成 输出,并将其作为查询结果发 回 给用户。
当用户继续进行查询时,它将通过相同的嵌入模型来创建嵌入,以查询该数据库中类似的 向量 嵌入 。向量 嵌入之间的相似性基于创建嵌入的原始内容。
想知道更多关于 其 在向量数据库中的工作原理吗 ?不妨了 解更多。
传统数据库以行和列的形式存储字符串 和 数字等 内容 。从传统数据库查询时,我们查询的是与查询匹配的行。然而,向量数据库处理的是向量 , 而不是字符串等 内容 。 向量 数据库还 运用 相似度度量 指标 , 该指标 用于帮助找到与查询最相似的 向量。
向量数据 库由不同的算法组成,这些算法都有助于进行近似最近邻 (A NN ) 搜索。这是通过散列、基于图的搜索或量化来完成的,它们被组装 到 一 条 管道 中,以 检索所查询 向量 的邻居。
结果取 决于它与查询的接近程度,因此考虑的主要因素是准确性和速度。如果查询输出慢,结果 就比较 准确。
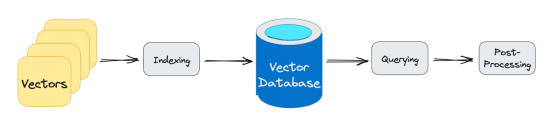
向量数据库查询要经历 的 三个主要阶段 :
1. 索引
如上例所述,一旦 向量 嵌入进入 到向量数据 库 中 ,它就会使用各种算法将 向量 嵌入映射到数据结构,以便更快地进行搜索。
2. 查询
一旦完成了 搜索, 向量 数据库将查询的 向量 与索引的 向量 进行比较,并 运用 相似性度量 指标 来查找最 近 邻。
3. 后处理
根据 您使用的向量数据库,向量数据库将对最后的最近邻进行后处理,以生成查询的最终输出 。 另外 , 还可能重新 排列最近邻, 供 将来 引用 。
结语
随着人工智能的不断发展和新系统的每周发布, 向量 数据库的 发展起到了 重要作用。向量数据库使公司能够更有效地与精确的相似度搜索进行交互,为用户提供更好更快的输出。
所以下次 您 在 ChatGPT 或 Google Bard 中输入查询时,想想它为 您 的查询输出结果 所经历 的过程。
原文标题: What are Vector Databases and Why Are They Important for LLMs? ,作者:Nisha Arya









